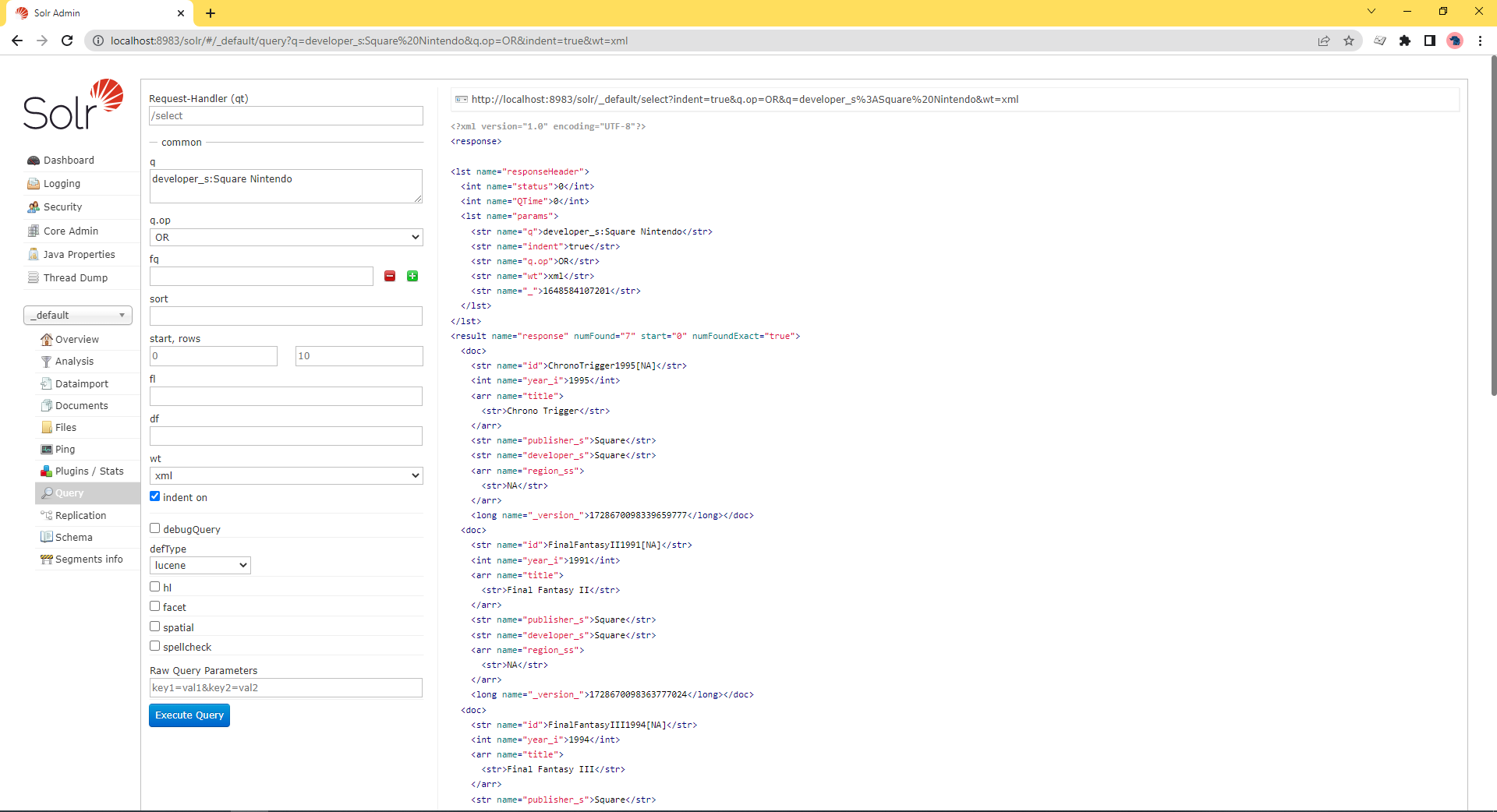
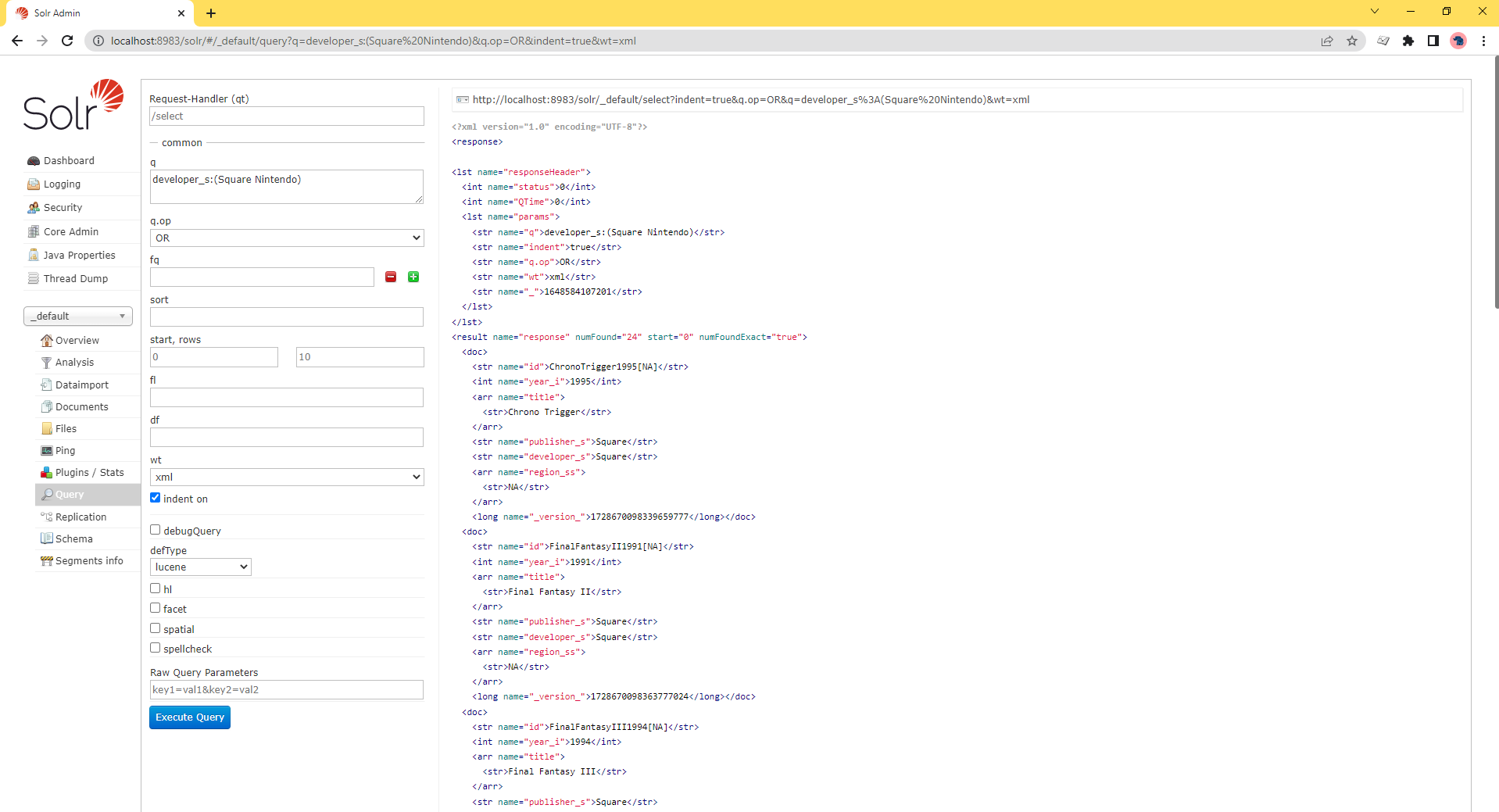
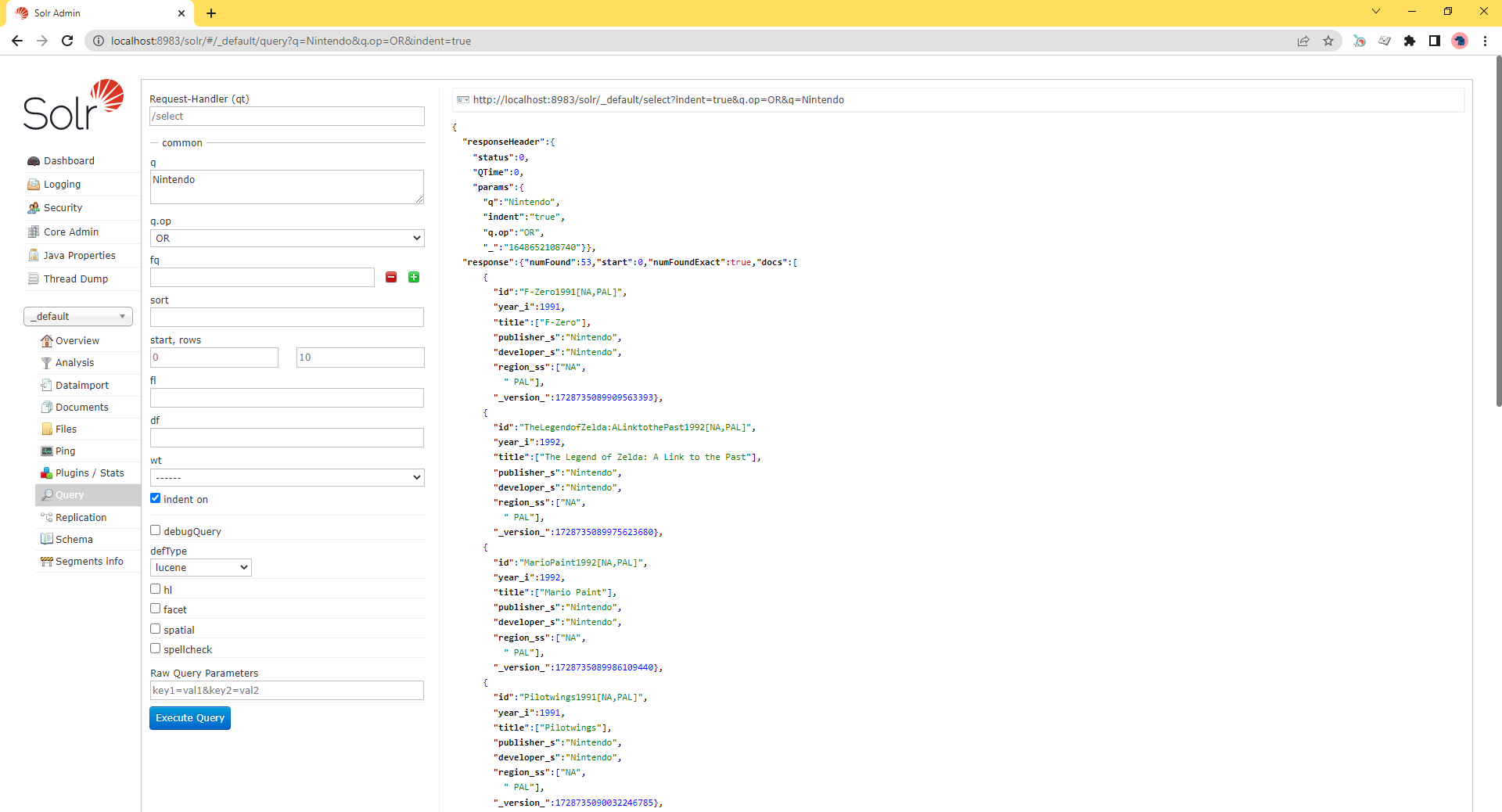
The difference between these two queries is small but significant. Words surrounded by the parenthesis are grouped to the field they follow. When the fields aren’t surrounded, “Nintendo” is searched for against the default field.
More information about how search queries are formed and processed can be found in the solr query parser documentation.
Since we can put documents into the index, and query them out, lets look into the details.
Each document will be composed of a list of its fields (though not all are required, depending on the query).
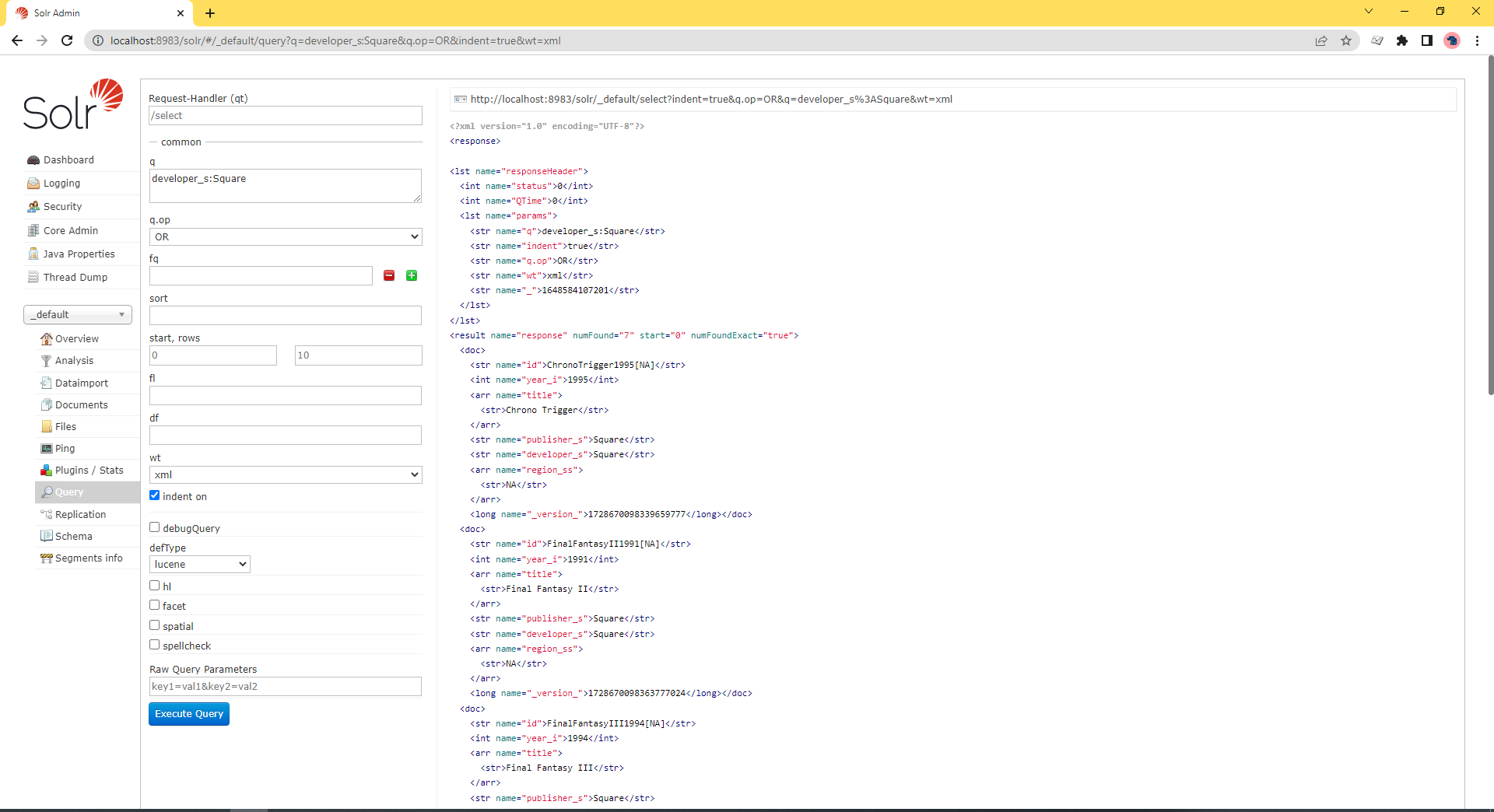
Lets take a look at the Chrono Trigger doc.
<doc>
<str name="id">ChronoTrigger1995[NA]</str>
<int name="year_i">1995</int>
<arr name="title">
<str>Chrono Trigger</str>
</arr>
<str name="publisher_s">Square</str>
<str name="developer_s">Square</str>
<arr name="region_ss">
<str>NA</str>
</arr>
<long name="_version_">1429159051143413760</long>
</doc>
The doc is composed of elements named with the type of data they contain. In this case we have an integer for year, strings for id, publisher_s and developer_s, and arrays of strings for title and region_ss. The names and values match those in the JSON.
{
"id" : "ChronoTrigger1995[NA]",
"year_i":"1995",
"title":"Chrono Trigger",
"publisher_t":"Square",
"developer_s":"Square",
"region_ss":"NA"
}
A few things might seem odd. The _i, _t, and _ss are telltale signs that we’re using a Solr concept called dynamic fields. These allow us to create fields as we need. The id and title fields are not dynamic and exist in every document. (We’ll see why in a bit.) When we compare the JSON to the XML we also see that JSON holds a single value for title and region_ss and they are arrays in XML. This is because the fields are specified as allowed to hold multiple values.
The managed-schema file.
So far we’re able to easily query a given column (NOTE: Queries are case sensitive in this case, as you may have noticed) and add data to the system. We did this without even modifying the default configuration; we just started Solr and threw information at it.
Solr’s ease of installation and startup alone makes the system worth considering, but this simple method is not without some problems. For example: if we execute a search with the query set to developer_s:square, we’ll get 0 results because strings and text are handled differently. Another example: a query for the word Nintendo (and nothing else) will return one result, the ill-fated monstrosity known as the Super Nintendo Scope 6.
Without diving into the very low level details, this is a problem with analyzers and copy fields. To fix this we’re going to venture into a new document: the managed-schema file. This file defines what Solr contains. Our current fields include id, title, multiple _s, and a _ss fields.
At the bottom of the managed-schema file we see some defined fields — in our case, we’re making use of the id and title fields.
<field name="_nest_path_" type="_nest_path_"/>
<field name="_root_" type="string" docValues="false" indexed="true" stored="false"/>
<field name="_text_" type="text_general" multiValued="true" indexed="true" stored="false"/>
<field name="_version_" type="plong" indexed="false" stored="false"/>
<field name="id" type="string" multiValued="false" indexed="true" required="true" stored="true"/>
<field name="title" type="text_general"/>
Then we created developer_s and publisher_s which match the dynamicField of name="*_s" as well as publisher_ss which made use of the name="*_ss" dynamic field.
<fields>
...
<dynamicField name="*_ss" type="strings" indexed="true" stored="true"/>
...
<dynamicField name="*_s" type="string" indexed="true" stored="true"/>
...
</fields>
The non-dynamic fields all will exist and store content that comes in matching their name. The dynamic fields act as catch-alls for a given combination of types and settings and allow you to create and query fields as needed without needing to update the schema.
Analyzers.
The managed-schema file also allows us to define how Solr works. In its current state, searching for developer_s:square without a capital S will return no results because the fieldType with name="string" doesn’t have any settings which tell Solr to modify or process the text before putting it in the index. We need to tell Solr to do something with the input so that queries case insensitive.
Copy fields.
Additionally, our failed “Nintendo” search did not specify a field, so the query assumed the default field — `name=”_text_”’ The only Super Nintendo game with the word “Nintendo” in the title was — ugh — Super Nintendo Scope 6.
This is the result of what are called copy fields. Copy Fields are settings to duplicate data being entered into a second field. This is done to allow the same text to be analyzed multiple ways.
With Solr, you can make your search more reliable by adding the following line at the very bottom.
<copyField source="*_s" dest="_text_"/>
This will take all of our dynamic string fields and add them to the _text_ field.
But it won’t work just yet. Since Copy Fields are processed at indexing time, we need to re-process all of the input data, which, like all updates to managed-schema, requires stopping and starting Solr.
Stopping and starting Solr.
solr restart -p 8983
Solr should be starting back up. When it finishes, re-run this command:
curl http://localhost:8983/solr/_default/update?commit=true -H "Content-Type: application/json" -T "snes.json" -X POST
Restarting Solr updates the schema configuration, and re-running the curl command sends all the data back at Solr to be processed again. Because all indexing occurs as documents are sent to Solr, any changes to the configuration will require re-submitting data to be indexed — hence the re-running of the curl command.
Going back to the query window we can test the recent indexing by searching for “Nintendo” (and nothing else) again. We now get 53 results, and now Super Nintendo Scope 6 has some company to live up to.